


title: Super Easy Automated Scraping with AWS Amplify published: true description: A tutorial on data scraping with AWS Amplify tags: AWS slug: aws-amplify-scraping canonical_url: swyx.io/aws-amplify-scraping
cover_image: cdn.hashnode.com/res/hashnode/image/upload/..
Too much of our most important data is ephemeral.
There are a lot of data points in our digital lives that only really exist as live updating numbers. They flash for a moment, and are then forever lost to history.
However these numbers would gain much more value if we add an extra dimension: time. This is why we love watching charts of github star histories and npm downloads. If we could only cheaply and easily automate tracking everything else, we would have a lot more megatrend and market share information available at our fingertips.
I have previously written about scraping with GitHub Actions, but that isn't really a scalable solution as it wasn't something git and GitHub Actions were really designed to do.
Today I want to share how to do data scraping with AWS Amplify.

High Level Architecture
Our demo project is going to be scraping Twitter follower count on a periodic basis and storing it in a database for later analysis. (But of course we can extend this to scraping anything and storing anywhere)
We're going to use the AWS Amplify CLI to spin this up in minutes:
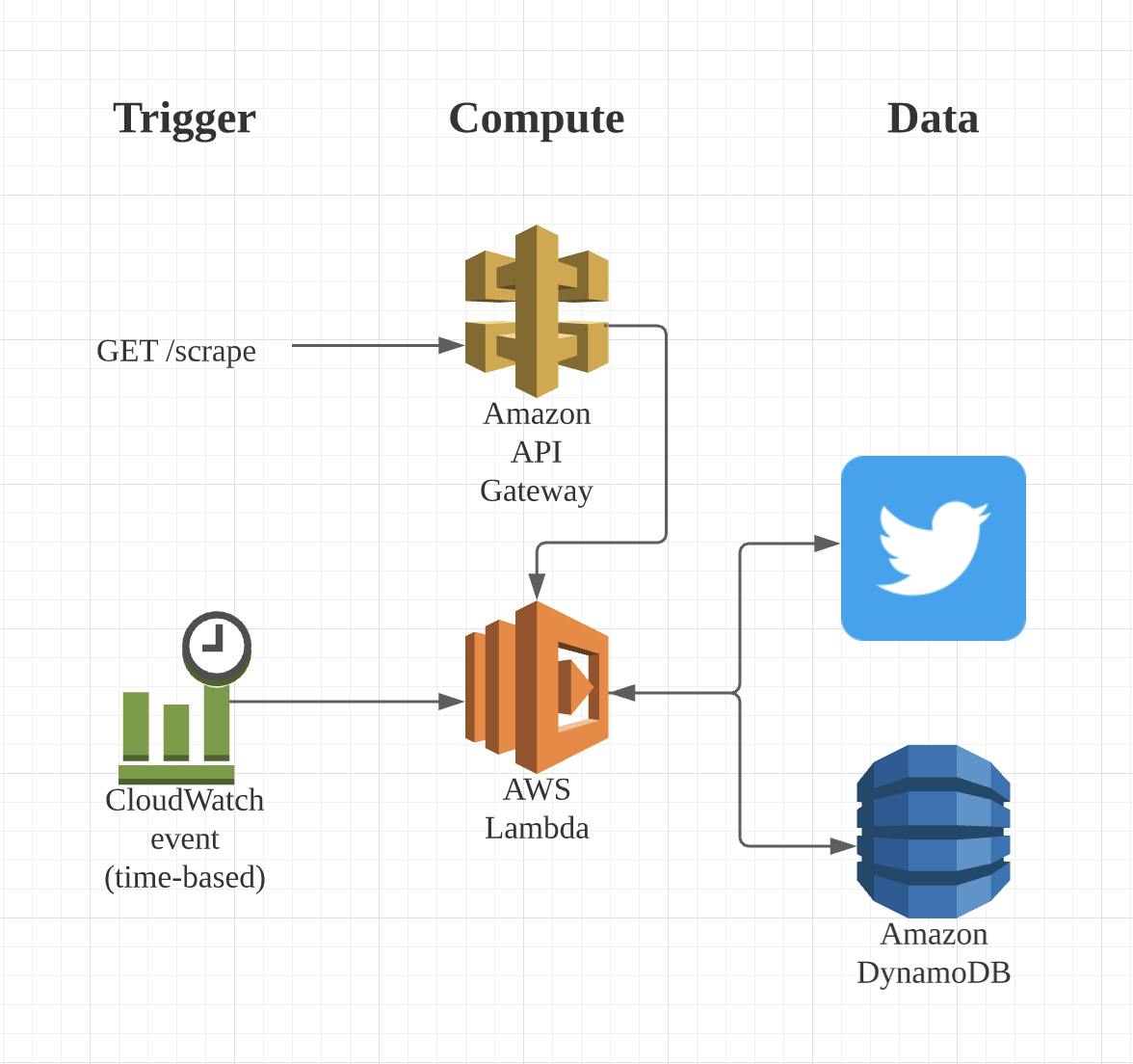
The heart of this is the AWS Lambda function we will write. It will fetch data from Twitter and then store it in DynamoDB. We'll have two ways to trigger a scrape - an event based trigger from CloudWatch, and a manual trigger from a public API (done via API Gateway).
Set Up
I'm going to assume you have the Amplify CLI installed and setup.
We'll start our amplify project and initialize our resources:
amplify init # choose all defaults
amplify add api # choose the options according to the below
In that one command, you can actually choose to set up the scheduled CloudWatch Lambda invocations and the DynamoDB database associated with that Lambda function as well. Pretty neat, right?
# STEP ONE: Creating API
? Please select from one of the below mentioned services: REST
? Provide a friendly name for your resource to be used as a label for this category in the project: scrape
? Provide a path (e.g., /book/{isbn}): /scrape
? Choose a Lambda source Create a new Lambda function
? Provide an AWS Lambda function name: scrape
? Choose the runtime that you want to use: NodeJS
? Choose the function template that you want to use: CRUD function for DynamoDB (Integration with API Gateway)
# STEP TWO: Creating Database
? Choose a DynamoDB data source option Create a new DynamoDB table
? Please provide a friendly name for your resource that will be used to label this category in the project: scrapingd
b
? Please provide table name: scrapingdb
? What would you like to name this column: date
? Please choose the data type: string
? Would you like to add another column? No
? Please choose partition key for the table: date
? Do you want to add a sort key to your table? No
? Do you want to add global secondary indexes to your table? No
? Do you want to add a Lambda Trigger for your Table? No
Successfully added DynamoDb table locally
# STEP THREE: Schedule function invocation
Available advanced settings:
- Resource access permissions
- Scheduled recurring invocation # <---- we want this!!
- Lambda layers configuration
? Do you want to configure advanced settings? Yes
? Do you want to access other resources in this project from your Lambda function? Yes
? Select the category storage
Storage category has a resource called scrapingdb
? Select the operations you want to permit for scrapingdb create, read, update
? Do you want to invoke this function on a recurring schedule? Yes
? At which interval should the function be invoked: Hourly
? Enter the rate in hours: 6
? Do you want to configure Lambda layers for this function? No
? Do you want to edit the local lambda function now? No
Successfully added resource scrape locally.
Develop
You can now work on the AWS Lambda function that you have just scaffolded. Here is the sample code that worked for me:
// amplify/backend/function/scrape/src/index.js
const fetch = require('node-fetch')
const cheerio = require('cheerio')
const util = require('util');
const AWS = require('aws-sdk')
AWS.config.update({ region: process.env.TABLE_REGION });
const dynamodb = new AWS.DynamoDB.DocumentClient();
const ddb = util.promisify(dynamodb.put);
let tableName = "scraperesults";
if(process.env.ENV && process.env.ENV !== "NONE") {
tableName = tableName + '-' + process.env.ENV;
}
exports.handler = async (event, context) => {
let data
try {
data = await (await fetch("https://twitter.com/swyx", {
headers: {
'User-Agent': "Googlebot/2.1 (+http://www.google.com/bot.html)"
}
})).text()
const $ = cheerio.load(data)
const count = Number($('.ProfileNav-item--followers .ProfileNav-value').attr('data-count'))
const Item = {
count,
date: (new Date()).toString()
}
const data = await ddb({
TableName: tableName,
Item: Item
})
return {
statusCode: 200,
body: JSON.stringify({message: 'data saved!', Item})
}
} catch (error) {
return {
statusCode: 500,
error
}
}
};
Make sure to install node-fetch and cheerio as these are new dependencies in your AWS Lambda function.
Test
As you develop your function, you'll want to test it locally without deploying it, so that you can have a fast iteration cycle. Amplify has basic function mocking - note it will not mock the DynamoDB part for you, unless you mock a GraphQL API (which we are not using here).
amplify mock function <function_name> --event "src/event.json" # this file only matters if you are trying to simulate an event payload to your lambda function
Deploy
Once you're happy with your setup working locally, you can push it up to the cloud:
amplify push
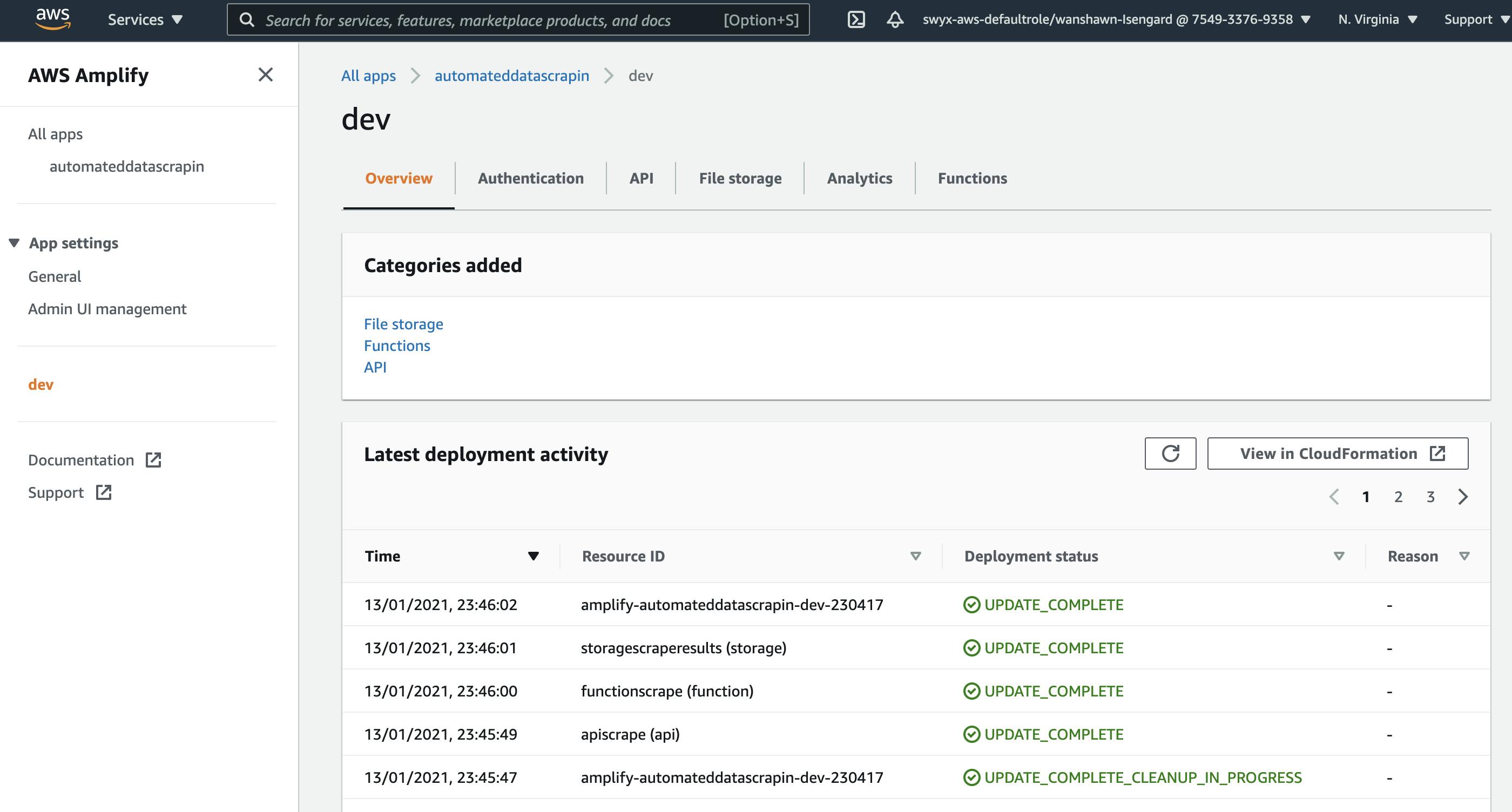
And it will be deployed and running! You'll be able to see your Amplify project in the Amplify Console (which you can also access via running amplify console in your terminal):
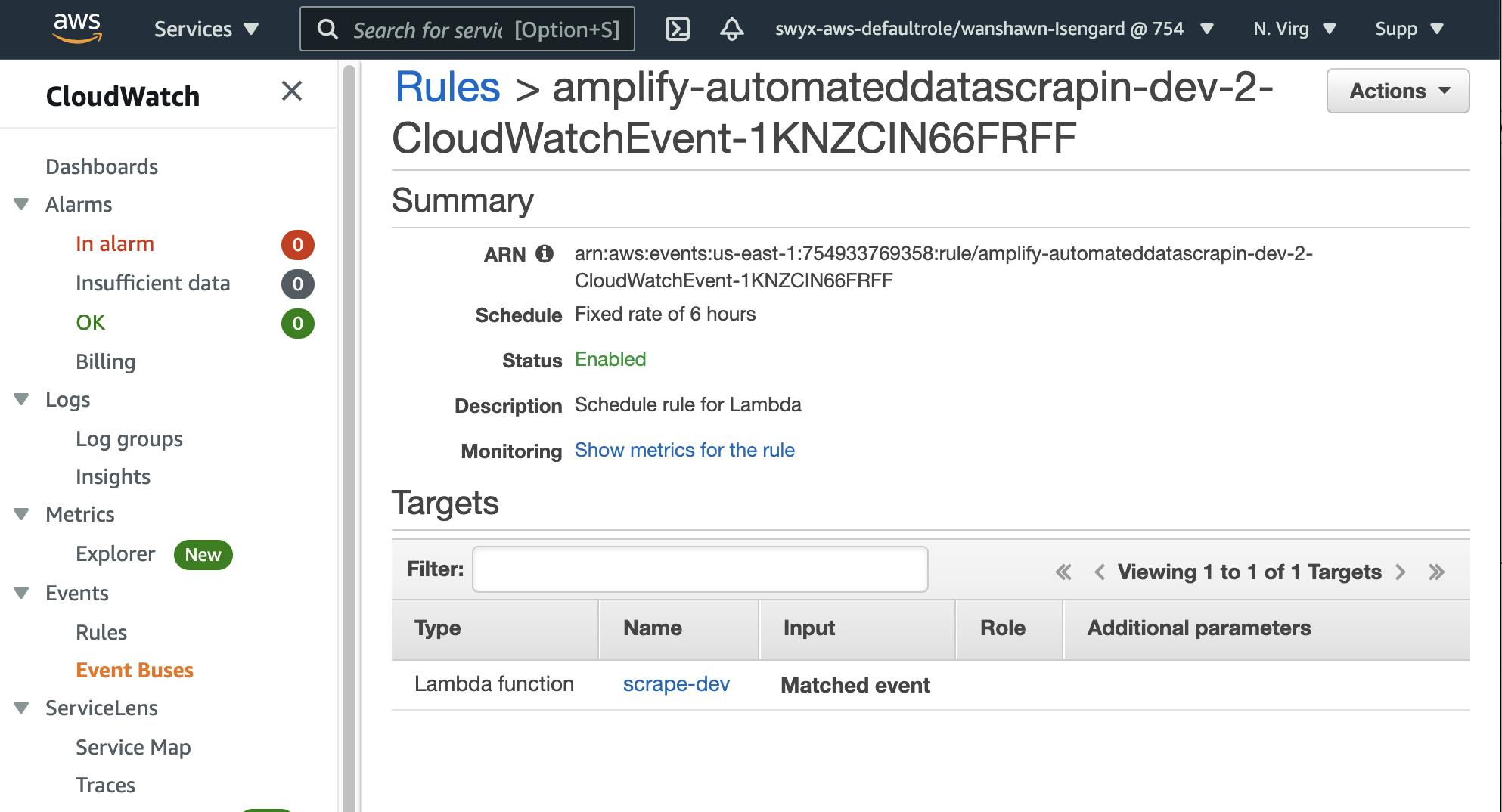
And you can even dive into the individual Lambda, API Gateway, DynamoDB, and CloudWatch consoles for full observability into the underlying services you have set up:
Takeaways
It's easier than ever to spin up custom serverless infrastructure to get stuff done!
Do note that a highly reliable implementation of this will probably need to run JS or ping an API instead of scraping HTML, and rotate IP's in case of rate limiting and IP blocking. I have more web scraping notes on my GitHub cheatsheet if you are interested in learning more.