

title: What drives Optimal Overhead? published: true description: The biggest unanswered question in the study of systems. tags: Research, Systems slug: optimal-overhead canonical_url: swyx.io/optimal-overhead
cover_image: cdn.hashnode.com/res/hashnode/image/upload/..
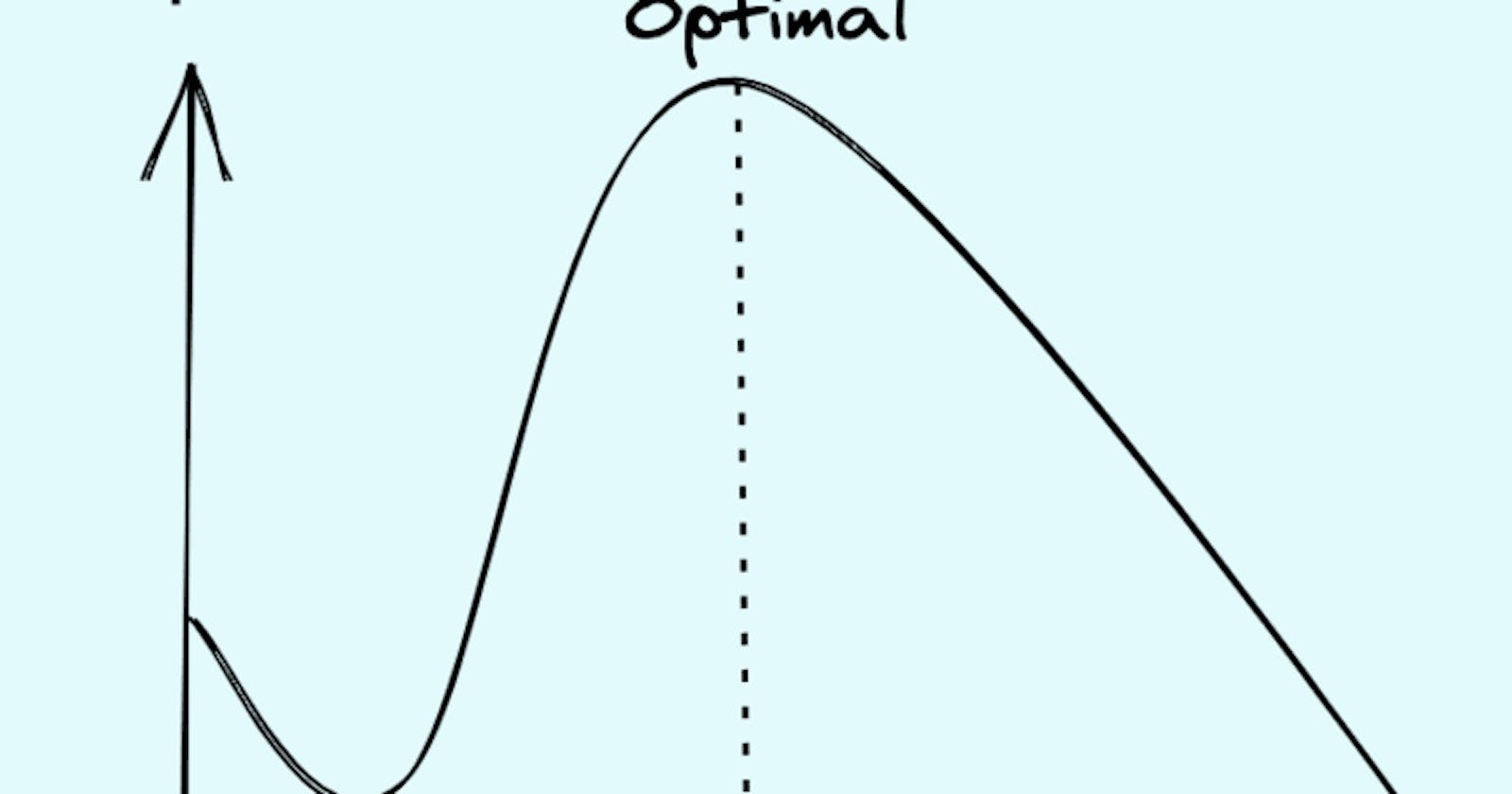
What determines the optimal amount of overhead in a system?
This question has been bothering me ever since I began my informal study of computer and human systems. Systems thinkers are usually very thoughtful types, but as far as I can tell nobody's answered it yet.
This strikes me as odd, because it is an incredibly important number to manage.

Defining Overhead
I use the word in the conceptual sense here, closer to StackOverflow than Wikipedia). I'm pretty poor at defining things – but it's important, so here's my attempt:
Pretend your job is to do as much as possible of a certain task (producing output), given limited resources (time, CPU, memory, bundle size, people...). Overhead is the percentage of resources you spend not directly producing — in order to do produce even more with the remaining resources.
Sometimes overhead is also known as "footprint".
Some Examples
Before I lose you, here are some examples of overhead (of course, these are very imprecise, just roll with it):
- Operating Systems: We could run our apps on "bare metal", but we don't. In this case the goal isn't necessarily running the most apps or running them the fastest; we use OSes to improve user and developer experience.
- Windows 10's idle CPU usage is 2-4% (high variability)
- MacOS is less conclusive, maybe 6% (high variability)
- iOS "System Storage" takes up 25% of a 16GB iPhone (less with more memory)
- Virtualization has between 9-35% overhead (or 1-5% of CPU and 5-10% Memory). Docker has minimal performance overhead and it seems so does Kubernetes (the learning curve overhead is a different question, discussed below).
- Cloudflare Workers abandon containers for isolates. If you believe the image shown, the process overhead inverts from ~90% to ~10%.
- Obviously the image is not drawn to scale, but it's clear the overhead reduction is large (If you're a knowledgeable reader, I'd love to get actual ballpark numbers on this)
- React takes about 8% of compute in apps, by FB's own numbers
- Management Overhead:
- 1 Manager should support 6-8 engineers, says Will Larson. Aka 12.5% to 16.7% overhead.
- Cal Newport takes 10-20 minutes to plan out every work day. Assuming an 8hr work day, that's just a 3% overhead.
- Every entrepreneur struggles with the balance between "working ON the business" and "working IN the business" (coined by Michael Gerber). I think a ratio of 1:4 works well (say 10%-25% overhead in reality).
- Marketing Overhead: Matt D'Avella says you should spend 80% of your time working on content, then 20% working on title, thumbnail, marketing.
Too Much, or Too Little?
We don't directly care about how much overhead we use; we just want to maximize output. But clearly everything about how we plan and do our jobs will be wildly different depending on whether optimal overhead is 5% or 50%. (This can serve as a very useful filter for choosing tech and architecture, for example.)
Increasing overhead often makes sense. This goes by many names: Slow down to speed up. Sharpen the saw. Automate repeated tasks.
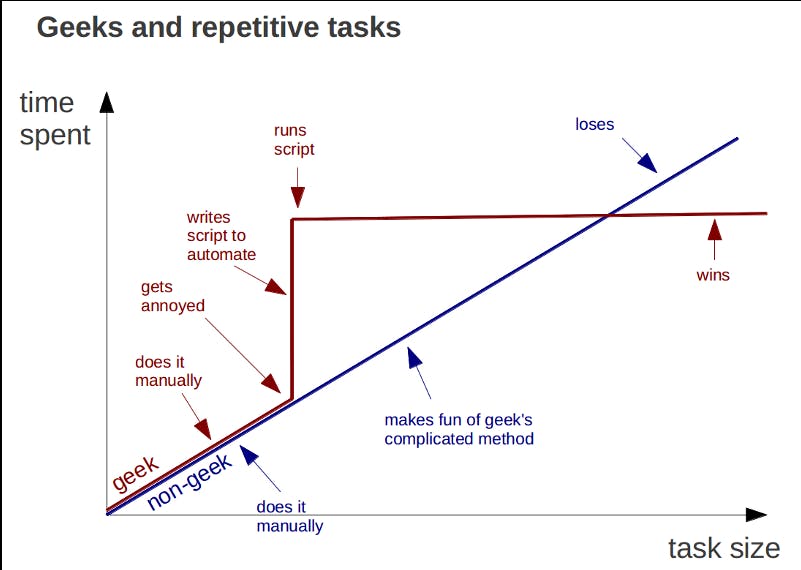
But sometimes the overhead isn't worth it, and we can't tell. Sometimes we should just be doing the thing rather than doing setup to do the thing. You see variants of this debate all over the place, from Virtual DOM is pure overhead to Do Things That Don't Scale.
By definition, overhead is indirectly linked to output. This link can be nonlinear, and noisy:
- Imagine if you were taught to keep 30% overhead, but decided to try dropping down to 10%, and observed no change in output efficiency. (like Uber did)
- You would go from spending 70% of your resources producing, to 90% of your resources producing, with the same output per resource. This would be a 29% increase in output you've been missing out on the entire time! You'd be pissed!
- And then imagine if someone else did it and got completely different results instead — and everyone was okay with it. No further study conducted.
That's our state of understanding of overhead in systems as of today.
This is closer to how real life overhead charts might look like:
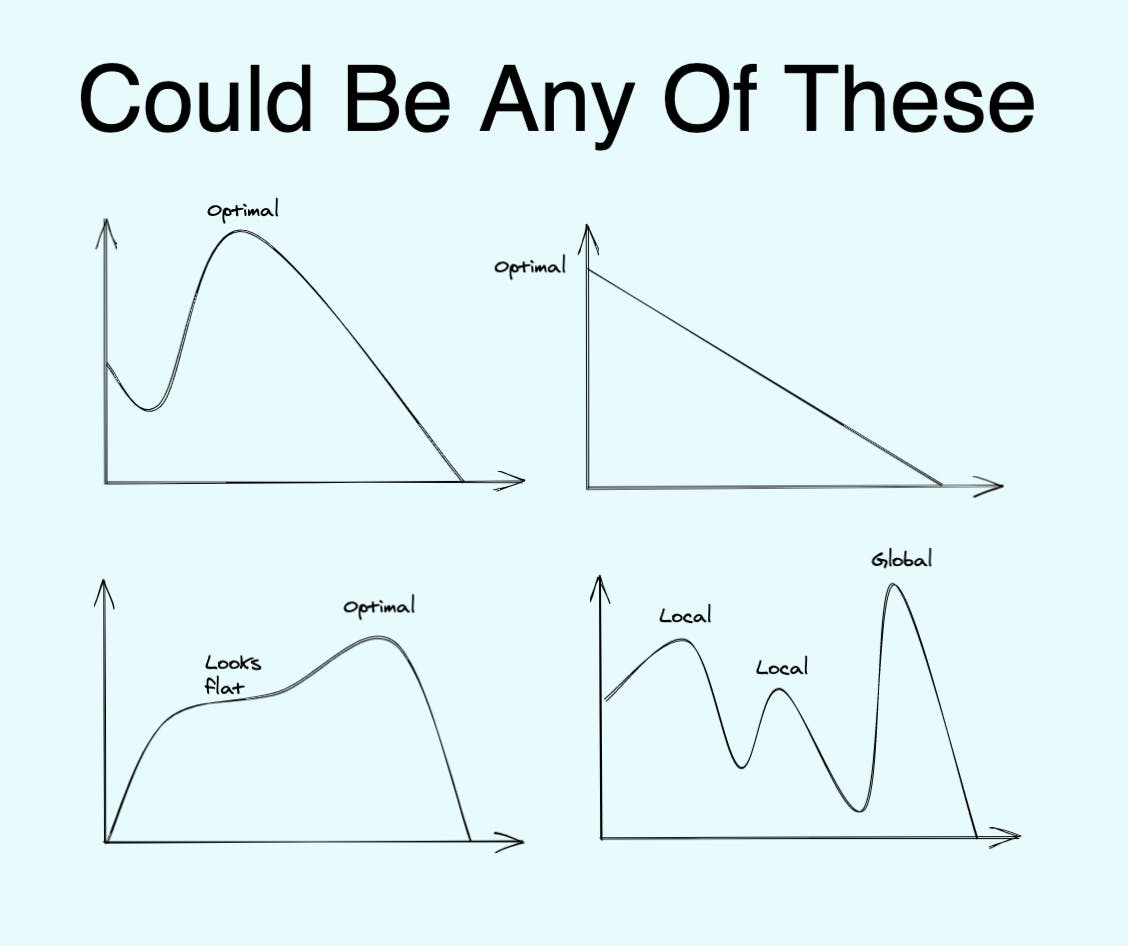
Imagine if we had a "Science of Overhead". I'd settle for just being able to do napkin math on it. A ballpark range for overhead would reduce our uncertainty and help us find optimal (or tolerable, see below) overhead.
Determinants
I don't have an answer. This post is me thinking aloud. But here are some hypotheses I am exploring.
Big O
Overhead is governed by Big O as well. It's not super meaningful to measure the storage overhead of an operating system in percentages, because it is a fixed size - O(1).
You can make an argument that virtualization overhead scales O(N) with N being the number of VMs.
Anything involving networking and communication suffers combinatorial/Metcalfe's law explosion, leading to nonlinearly increasing O(N^2) or worse inefficiency.
Learning Curve
A unique form of overhead is something you can pay once and amortize across repeated projects, instead of only having a useful life of one project. This is known as a learning curve.
All frameworks bear this sort of overhead: For any one project, you might be able to get things done faster AND have faster running code, if you just did the project using "vanilla" code instead of learning the framework and then doing the project. You only see the benefits down the line once you work on multiple similar projects.
You might also then overinvest in the framework, only to find out that other projects aren't a fit, or, vice versa, the framework doesn't scale for your needs in some unforeseen way.
There are two unknowns to learn:
- learning about the problem
- learning about various solutions
One very good reason to use a framework is that it encodes more knowledge about the problem than you may have. But it can also be a crutch that gets in the way of you learning about the problem in the first place. And when you know enough about the problem and enough about the limitations of existing solutions, you may be forced to make your own.
All of this is very familiar to experienced programmers.
And all of this is (tiresome, sometimes very unproductive) overhead.
The primary challenge of "learning curve" type overhead isn't the amortization math. This is intuitive.
What is particularly intractable is Knightian uncertainty around not knowing what you don't know. By definition, if you haven't learned it yet, you may not really know how to evaluate it fully and have to rely on secondhand reports and endorsements.
I hold out faith that this is a manageable, if not solvable problem. I have a strong suspicion that becoming a technical or people leader means developing some skill in managing for unknowns. It is a truism that scaling yourself, beyond just you, means you have to manage people whose jobs you have never done and technologies whose alternatives you have never used.
Note: Done badly, the above can be a particularly loathsome form of bullshit job. And yes — this includes product management and blogging — both roles that I perform. Always beware Gell-Mann Amnesia.
Humans vs Machines
You might be tempted to conclude that human systems naturally have higher overhead, as I was. Joel Spolsky's discussion of Development Abstraction Layers noted:
"It is not a coincidence that the Roman army had a ratio of four servants for every soldier. This was not decadence. Modern armies probably run 7:1."
Will Larson also commented that Parkinson's Law originated from a similar observation that the British Navy's bureaucracy kept growing at the same rate regardless of the underlying work declining by 2/3rds.
Side note: David Golden notes that military "tooth to tail" ratios aren't really the same thing as overhead.
But it's not always true. The US civil service is about 2% of the overall US labor force (you may be surprised to find, as I was, that Singapore's equivalent "overhead" is ~4%). Something that some operating systems would be proud of.
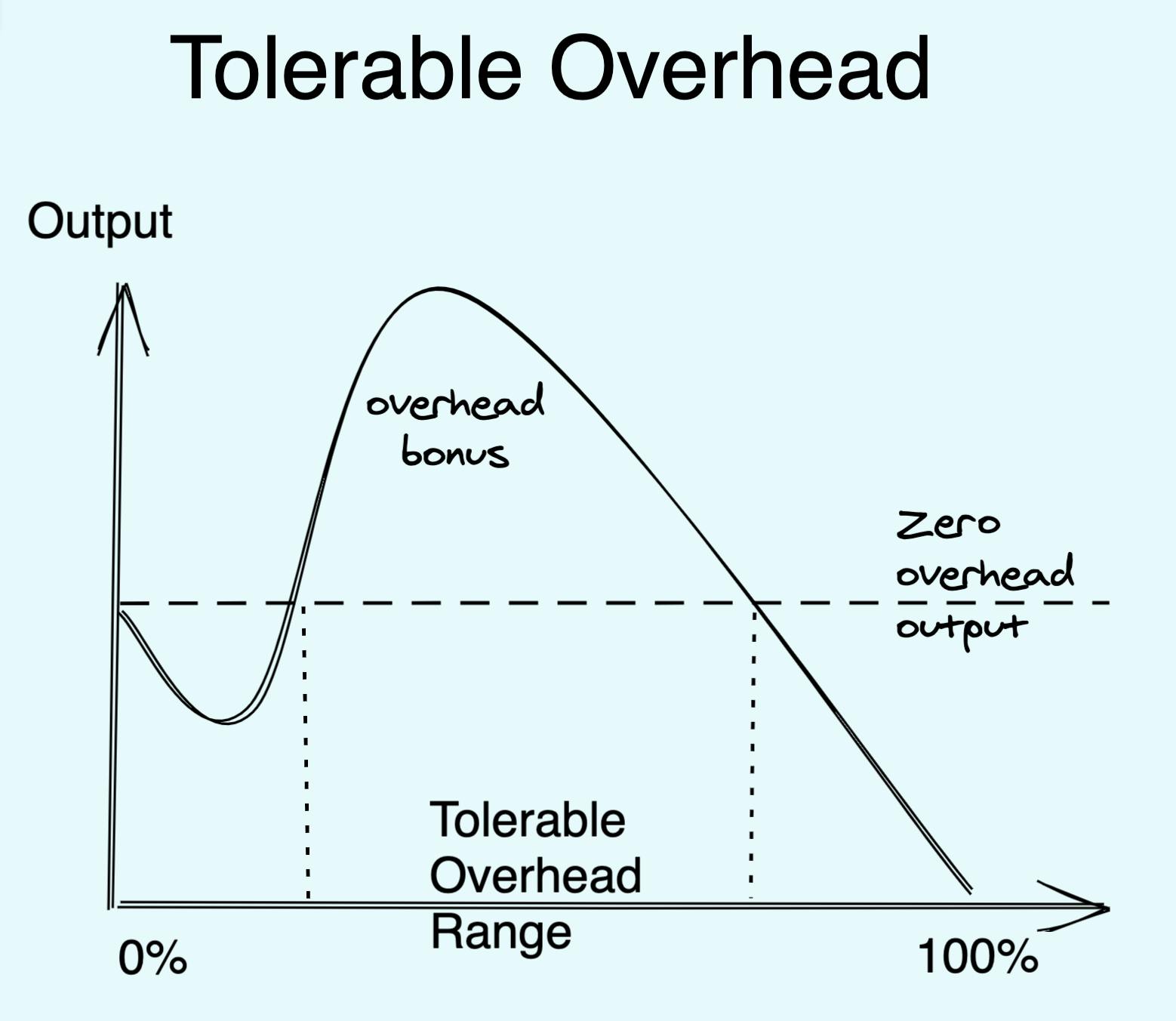
Tolerable Overhead
Perhaps it is too much of an optimization exercise to aim for optimal overhead, given how noisy this whole process is. A lower bar we can aim for is Tolerable Overhead, suggested by David Golden. To me this is like a "first do no harm" principle of overhead - make sure you are at least no less productive with overhead than you were without it.
Postscript: Redundancy vs Overhead
You can find examples of "redundancy" everywhere in distributed systems. MongoDB recommends 3 member replica sets, but Google famously requires 5 nodes for fault tolerance. Of course by nature these are >100% numbers - and David Golden rightly pointed out to me that they aren't comparable to overhead.
Related Reads
I will update this post with more reads and numbers as I come across them. Ultimately I'd like to achieve a good reference table like this epic Dan Luu post on Computer Latency.
I did a fun talk about Svelte and the Great Space Elevator where I discussed how we pay for overhead in frontend frameworks.